成为VIP
成为VIP本篇文章是MySQL的进阶学习,带大家详细了解一下创建更合适索引的方法,希望对大家有所帮助!

不要当库里的数据较多的时候才能知道索引的重要性,更不要当库里的数据更多的时候才能知道合适的索引重要性。本文介绍下怎么创建高效且合适的索引。【相关推荐:explain详解一篇

2. 尽量使用主键查询,而不是其他索引,主键查询不会出现回表查询。
我们所有的表基本都会有主键的,所以平时开发中能用索引就用索引,能用主键索引就用主键索引。
3. 使用前缀索引
很多时候我们的索引其实都是字符串,不可避免会出现长字符串,就会导致索引占用过大,降低其效率。尤其是对于blob,text, varchar这样的长列。这时候处理方式就是不使用字段的全值作为索引,而是只取其前半部分即可(选择的这部分前缀索引的选择性接近于整个列)。这样可以大大减少索引空间,从而提高效率,坏处就是降低了索引的选择性。
索引选择性:不重复的索引值和数据表记录总数的比值(#T),范围从1/#T到1之间。索引的选择性越高查询效率也高,因为数据的区分度很高,可以过滤掉更多的行。唯一性索引的选择性是1,其性能也最好。
例如公司的员工表中邮箱字段,一个公司的邮箱后缀都是一样的如xxxx@qq.com, 其实用邮箱作为索引有效的就xxxx部分,因为@qq.com都是一样的,对索引是无意义的,明显只用xxxx作为索引,其选择性和整个值的是一样的,但是xxxx作为索引明显就会减少索引空间。
下面我们已employee表为例子(表结构和数据看文末)
我们以email字段建立索引为例:
这个数据的邮箱其实是手机号+@qq.com为例的,其实前11位后面都是相同的。我用下面的sql来看看这些数据的选择性(分别取前10,11,12)位计算。
-- 当是11个前缀的时候选择性是1,在增加字段长度,选择性也不会变化 select count(distinct left(email,10))/count(*) as e10, count(distinct left(email,11))/count(*) as e11, count(distinctleft(email,12))/count(*) as e12 from employee;

从上图我们可以看出前10,前11,前12的选择性分别是0.14,1.0,1.0 ,在第11位的时候索引选择性是最高的1,就没必要使用全部作为索引,增加了索引的空间。
-- 创建前缀索引 alter table employee add key(email(11));
我们也可以使用count计算频率来统计(出现的次数越少,说明重复率越低,选择性越大)
-- 查找前缀出现的频率 select count(*) as cnt,left(email,11) as pref from employee group by pref order by cnt desc limit 10;

4.使用索引扫描来排序
我们经常会有排序的需求,使用order by 但是order by是比较影响性能的,它是通过把数据加载到内存去排序的,如果数据量很大内存放不下,只能分多次处理。但是索引本身就是有序的,直接通过索引完成排序更省事。
扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录,但如果索引不能覆盖查询所需的所有列时,就不得不每扫描一条索引记录就回表查询一次对应行,这基本都是随机IO。因此按索引顺序读取数据的速度通常比顺序的全表扫描慢。
mysql可以使用同一个索引即满足排序,又用于查找行。如果可以的话请考虑建立这种索引。
只有当索引列顺序和order by子句的顺序完全一致,并且所有列的排序方向(倒叙或者正序)都是一样的,mysql才能使用索引对结果做排序。如果查询需要关联多张表,只有当order by子句的字段全是第一张表时才能使用索引排序。order by 查询同时也需要满足组合索引的最左前缀,否则也不能使用索引排序。
其实在开发中主要注意两点:
- where条件中的字段和order by中的字段能够是组合索引而且满足最左前缀。
- order by中的字段的顺序需要一致,不能存在desc,又存在asc。
5. union all ,in,or都能够使用索引,但是推荐使用in

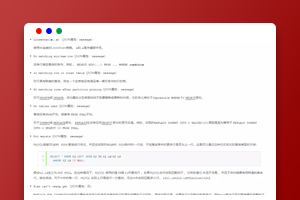
如上union all 会有两次执行,而in 和or只有一次。同时看出or和in的执行计划是一样的,\
但是我们在看一下他们的执行时间。如下图使用set profiling=1可以看到详细时间,使用show profiles 查看具体时间。下图看出or的时间0.00612000,in的时间0.00022800,差距还是很大的(测试的表数据只有200行)

union all: 查询分为了两阶段,其实还有一个union,在平时开发中必须使用到union的时候推荐使用union all,因为union中多出了distinct去重的步骤。所以尽量用union all。
6. 范围列可以用到索引
范围的条件:>,>=,<,<=,between
范围列可以用到索引,但是范围列后面的列就无法用到索引了(索引最多用于一个范围列)
比如一个组合索引age+name 如果查询条件是where age>18 and name="纪"后面的name是用不到的索引的。
曾经面试被问到不等于是否能够走某个索引,平时没有注意过也没有回答成功,这次亲自做个实验,关于结论请看文末。
7. 强制类型转换会全表扫描
我在employee表中定义了mobile字段是varchar类型且建立索引,我分别用数字和字符串查询.
看看结果: 两者type是不一样的,而且只有字符串才用到索引。
如果条件的值的类型和表中定义的不一致,那么mysql会强制进行类型转换,但是结果是不会走索引,索引在开发中我们需要根据自己定义的类型输入对应的类型值。

8. 数据区分度不高,更新频繁的字段不宜建立索引
- 索引列更新会变更B+树的,频繁更新的会大大降低数据库性能。
- 类似于性别这类(只有男女,或者未知),不能有效过滤数据。
- 一般区分度在80%以上就可以建立索引,区分度可以使用count(distinct(列名))/count(*)
9. 创建索引的列不允许为null,可能会得到不符合预期的结果
也就是建立索引的字段尽量不要为空,可能会有些意想不到的问题,但是实际工作中也不太可能不为空,所以根据实际业务来处理吧,尽量避免这种情况。
10. 当需要进行表连接的时候,最好不要超过三张表
表连接其实就是多张表循环嵌套匹配,是比较影响性能的, 而且需要join的字段数据类型必须一致,提高查询效率。关于表连接原理后面专门写一篇吧。
11. 能使用limit的时候尽量使用limit。
limit的作用不是仅仅用了分页,本质作用是限制输出。
limit其实是挨个遍历查询数据,如果只需要一条数据添加 limit 1的限制,那么索引指针找到符合条件的数据之后就停止了,不会继续向下判断了,直接返回。如果没有limit,就会继续判断。
但是如果分页取1万条后的5条limit 10000,10005 就需要慎重了,他会遍历1万条之后取出5条,效率很低的。小技巧:如果主键是顺序的,可以直接通过主键获取分页数据。
12. 单表索引尽量控制在5个内
建立/维护索引也是需要代价的,也需要占用空间的。索引并不是越多越好,要合理使用索引。
13. 单个组合索引的字段个数不宜超过5个
字段越多,索引就会越大,占用的存储空间就越多。
补充
关于不等于是否走索引的问题
结论:只有主键会走,唯一键和普通索引都不会走。
我在employee表中建了唯一索引employee_num和联合索引employee_num+name,结果就是下图的执行情况。

employee表结构
CREATE TABLE `employee` ( `employee_id` bigint(20) NOT NULL AUTO_INCREMENT, `employee_num` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '员工编码', `name` varchar(60) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '员工姓名', `email` varchar(60) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL COMMENT '电子邮件', `mobile` varchar(60) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NULL DEFAULT NULL COMMENT '移动电话', `gender` tinyint(1) NOT NULL COMMENT '性别, 0: 男 1: 女', PRIMARY KEY (`employee_id`) USING BTREE, INDEX `email`(`email`(11)) USING BTREE, INDEX `employee_u1`(`employee_num`, `name`) USING BTREE, UNIQUE INDEX `employee_u2`(`employee_num`) USING BTREE, INDEX `employee_u3`(`mobile`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci COMMENT = '员工表' ROW_FORMAT = Dynamic;
employee数据如下:
INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (10, '001', '员工A', '15500000001@qq.com', '15500000001', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (11, '002', '员工B', '15500000002@qq.com', '15500000002', 0); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (12, '003', '员工C', '15500000003@qq.com', '15500000003', 0); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (13, '004', '员工D', '15500000004@qq.com', '15500000004', 0); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (14, '005', '员工E', '15500000005@qq.com', '15500000005', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (15, '006', '员工F', '15500000006@qq.com', '15500000006', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (16, '007', '员工G', '15500000007@qq.com', '15500000007', 0); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (17, '008', '员工H', '15500000008@qq.com', '15500000008', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (18, '009', '员工I', '15500000009@qq.com', '15500000009', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (19, '010', '员工J', '15500000010@qq.com', '15500000010', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (20, '011', '员工K', '15500000011@qq.com', '15500000011', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (21, '012', '员工L', '15500000012@qq.com', '15500000012', 1); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (22, '013', '员工M', '15500000013@qq.com', '15500000013', 0); INSERT INTO `sakila`.`employee`(`employee_id`, `employee_num`, `name`, `email`, `mobile`, `gender`) VALUES (23, '014', '员工N', '15500000014@qq.com', '15500000014', 1);
更多编程相关知识,请访问:编程视频!!
以上就是MySQL进阶学习:详解创建高效且合适索引的方法的详细内容,更多请关注亿码酷站其它相关文章!
<!–
—–文章转载自PHP中文网如有侵权请联系ymkuzhan@126.com删除
本文永久链接地址:https://www.ymkuzhan.com/43993.html