成为VIP
成为VIP本篇文章带大家了解MySQL中SQL的执行流程,看看MySQL 是如何执行一条查询语句的?希望对大家有所帮助!
插图")
对于一个开发工程师来说,了解一下 MySQL 是如何执行一条查询语句的,我想是非常有必要的。【相关推荐:mysql视频教程】
首先我们要了解一下MYSQL的体系架构是什么样子的?然后再来聊聊一条查询语句的执行流程是如何?
MYSQL体系结构
先看一张架构图,如下:

模块详解
-
Connector:用来支持各种语言和 SQL 的交互,比如 PHP,Python,Java 的 JDBC; -
Management Serveices & Utilities:系统管理和控制工具,包括备份恢复、MySQL 复制、集群等; -
Connection Pool:连接池,管理需要缓冲的资源,包括用户密码权限线程等等; -
SQL Interface:用来接收用户的 SQL 命令,返回用户需要的查询结果 ; -
Parser:用来解析 SQL 语句; -
Optimizer:查询优化器; -
Cache and Buffer:查询缓存,除了行记录的缓存之外,还有表缓存,Key 缓存,权限缓存等等; -
Pluggable Storage Engines:插件式存储引擎,它提供 API 给服务层使用,跟具体的文件打交道。
架构分层
把 MySQL 分成三层,跟客户端对接的连接层,真正执行操作的服务层,和跟硬件打交道的存储引擎层。

连接层
我们的客户端要连接到 MySQL 服务器 3306 端口,必须要跟服务端建立连接,那么管理所有的连接,验证客户端的身份和权限,这些功能就在连接层完成。
服务层
连接层会把 SQL 语句交给服务层,这里面又包含一系列的流程:
比如查询缓存的判断、根据 SQL 调用相应的接口,对我们的 SQL 语句进行词法和语法的解析(比如关键字怎么识别,别名怎么识别,语法有没有错误等等)。
然后就是优化器,MySQL 底层会根据一定的规则对我们的 SQL 语句进行优化,最后再交给执行器去执行。
存储引擎
存储引擎就是我们的数据真正存放的地方,在 MySQL 里面支持不同的存储引擎。再往下就是内存或者磁盘。
SQL的执行流程
以一条查询语句为例,我们来看下 MySQL 的工作流程是什么样的。
select name from user where id=1 and age>20;
首先咱们先来看一张图,接下来的过程都是基于这张图来讲的:

连接
程序或者工具要操作数据库,第一步要跟数据库建立连接。
在数据库中有两种连接:
- 短连接:短连接就是操作完毕以后,马上 close 掉。
- 长连接:长连接可以保持打开,减少服务端创建和释放连接的消耗,后面的程序访问的时候还可以使用这个连接。
建立连接是比较麻烦的,首先要发送请求,发送了请求要去验证账号密码,验证完了要去看你所拥有的权限,所以在使用过程中,尽量使用长连接。
保持长连接会消耗内存。长时间不活动的连接,MySQL 服务器会断开。可以使用sql语句查看默认时间:
show global variables like 'wait_timeout';
这个时间是由 wait_timeout 来控制的,默认都是 28800 秒,8 小时。
查询缓存
MySQL 内部自带了一个缓存模块。执行相同的查询之后我们发现缓存没有生效,为什么?MySQL 的缓存默认是关闭的。
show variables like 'query_cache%';
默认关闭的意思就是不推荐使用,为什么 MySQL 不推荐使用它自带的缓存呢?
主要是因为 MySQL 自带的缓存的应用场景有限:
第一个是它要求 SQL 语句必须一模一样,中间多一个空格,字母大小写不同都被认为是不同的的 SQL。
第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对于有大量数据更新的应用,也不适合。
所以缓存还是交给 ORM 框架(比如 MyBatis 默认开启了一级缓存),或者独立的缓存服务,比如 Redis 来处理更合适。
在 MySQL 8.0 中,查询缓存已经被移除了。
语法解析和预处理
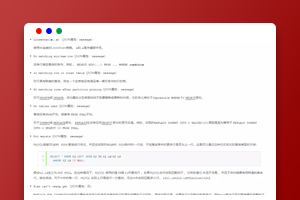
为什么一条 SQL 语句能够被识别呢?假如随便执行一个字符串 hello,服务器报了一个 1064 的错:
[Err] 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'hello' at line 1
这个就是 MySQL 的解析器和预处理模块。
这一步主要做的事情是对语句基于 SQL 语法进行词法和语法分析和语义的解析。
词法解析
词法分析就是把一个完整的 SQL 语句打碎成一个个的单词。
比如一个简单的 SQL 语句:select name from user where id = 1 and age >20;

它会将 select 识别出来,这是一个查询语句,接下来会将 user 也识别出来,你是想要在这个表中做查询,然后将 where 后面的条件也识别出来,原来我需要去查找这些内容。
语法分析
语法分析会对 SQL 做一些语法检查,比如单引号有没有闭合,然后根据 MySQL 定义的语法规则,根据 SQL 语句生成一个数据结构。这个数据结构我们把它叫做解析树(select_lex)。
就比如英语里面的语法 “我用 is , 你用 are ”这种,如果不对肯定是不可以的,语法分析之后发现你的 SQL 语句不符合规则,就会收到 You hava an error in your SQL syntax 的错误提示。
预处理器
如果写了一个词法和语法都正确的 SQL,但是表名或者字段不存在,会在哪里报错? 是在数据库的执行层还是解析器?比如:select * from hello;
还是在解析的时候报错,解析 SQL 的环节里面有个预处理器。它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名, 保证没有歧义。预处理之后得到一个新的解析树。
查询优化器
一条SQL语句是不是只有一种执行方式?或者说数据库最终执行的SQL是不是就是我们发送的 SQL?
这个答案是否定的。一条 SQL 语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选择哪一种去执行?根据什么判断标准去选择?
这个就是 MySQL 的查询优化器的模块(Optimizer)。 查询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选 择一种最优的执行计划,MySQL 里面使用的是基于开销(cost)的优化器,那种执行计划开销最小,就用哪种。
可以使用这个命令查看查询的开销:
show status like 'Last_query_cost';
MySQL 的优化器能处理哪些优化类型呢?
举两个简单的例子:
1、当我们对多张表进行关联查询的时候,以哪个表的数据作为基准表。
2、有多个索引可以使用的时候,选择哪个索引。
实际上,对于每一种数据库来说,优化器的模块都是必不可少的,他们通过复杂的算法实现尽可能优化查询效率的目标。但是优化器也不是万能的,并不是再垃圾的 SQL 语句都能自动优化,也不是每次都能选择到最优的执行计划,大家在编写 SQL 语句的时候还是要注意。
执行计划
优化器最终会把解析树变成一个执行计划(execution_plans),执行计划是一个数据结构。当然,这个执行计划不一定是最优的执行计划,因为 MySQL 也有可能覆盖不到所有的执行计划。
我们怎么查看 MySQL 的执行计划呢?比如多张表关联查询,先查询哪张表?在执行查询的时候可能用到哪些索引,实际上用到了什么索引?
MySQL 提供了一个执行计划的工具。我们在 SQL 语句前面加上 EXPLAIN,就可以看到执行计划的信息。
EXPLAIN select name from user where id=1;
存储引擎
在介绍存储引擎先来问两个问题:
存储引擎基本介绍
在关系型数据库里面,数据是放在表 Table 里面的。我们可以把这个表理解成 Excel 电子表格的形式。所以我们的表在存储数据的同时,还要组织数据的存储结构,这个存储结构就是由我们的存储引擎决定的,所以我们也可以把存储引擎叫做表类型。
在 MySQL 里面,支持多种存储引擎,他们是可以替换的,所以叫做插件式的存储引擎。为什么要支持这么多存储引擎呢?一种还不够用吗?
在 MySQL 里面,每一张表都可以指定它的存储引擎,而不是一个数据库只能使用一个存储引擎。存储引擎的使用是以表为单位的。而且,创建表之后还可以修改存储引擎。
如何选择存储引擎?
-
如果对数据一致性要求比较高,需要事务支持,可以选择 InnoDB。
-
如果数据查询多更新少,对查询性能要求比较高,可以选择 MyISAM。
-
如果需要一个用于查询的临时表,可以选择 Memory。
-
如果所有的存储引擎都不能满足你的需求,并且技术能力足够,可以根据官网内部手册用 C 语言开发一个存储引擎。(https://dev.mysql.com/doc/internals/en/custom-engine.html%EF%BC%89 )
执行引擎
谁使用执行计划去操作存储引擎呢?这就是执行引擎(执行器),它利用存储引擎提供的相应的 API 来完成操作。
为什么我们修改了表的存储引擎,操作方式不需要做任何改变?因为不同功能的存储引擎实现的 API 是相同的。
最后把数据返回给客户端,即使没有结果也要返回。
栗子
还是以上面的sql语句为例,再来梳理一下整个sql执行流程。
select name from user where id = 1 and age >20;
-
通过连接器查询当前执行者的角色是否有权限,进行查询。如果有的话,就继续往下走,如果没有的话,就会被拒绝掉,同时报出
Access denied for user的错误信息; -
接下来就是去查询缓存,首先看缓存里面有没有,如果有呢,那就没有必要向下走,直接返回给客户端结果就可以了;如果缓存中没有的话,那就去执行语法解析器和预处理模块。( MySQL 8.0 版本直接将查询缓存的整块功能都给删掉了)
-
语法解析器和预处理主要是分析sql语句的词法和语法是否正确,没啥问题就会进行下一步,来到查询优化器;
-
查询优化器就会对sql语句进行一些优化,看哪种方式是最节省开销,就会执行哪种sql语句,上面的sql有两种优化方案:
- 先查询表 user 中 id 为 1 的人的姓名,然后再从里面找年龄大于 20 岁的。
- 先查询表 user 中年龄大于 20 岁的所有人,然后再从里面找 id 为 1 的。
-
优化器决定选择哪个方案之后,执行引擎就去执行了。然后返回给客户端结果。
更多编程相关知识,请访问:编程视频!!
以上就是深入解析MySQL中SQL的执行流程(图文结合)的详细内容,更多请关注亿码酷站其它相关文章!
<!–插图5")
—–文章转载自PHP中文网如有侵权请联系ymkuzhan@126.com删除
本文永久链接地址:https://www.ymkuzhan.com/46152.html